כולנו כבר נתקלנו בזה: שאלנו את הצ’אטבוט שאלה פשוטה ותוך שניות מתקבלת תשובה שנשמעת בטוחה ומדויקת, אבל היא לגמרי לא נכונה! בעולם הבינה המלאכותית קוראים לזה “הזיות בינה מלאכותית” (AI Hallucinations), מצב שבו מודל שפה ממציא עובדות, מצטט מקורות שלא קיימים או מערבב נתונים בצורה שגויה.
מחקר חדש של חוקרים מ-OpenAI וג’ורג’יה טק, שהתפרסם בספטמבר 2025, מראה שהזיות כאלה הן לא בגדר תקלה טכנית זמנית, אלא תוצאה בלתי נמנעת של אופן האימון והמדידה של המודלים (לינק למחקר המלא). אז למה זה קורה ואיך זה משפיע על עתיד החיפוש?
למה הזיות AI בכלל קורות?
החוקרים מדמים את זה למצב של “מבחן אמריקאי” בו לכל שאלה כמה תשובות אבל רק אחת מהן נכונה – גם כשסטודנט לא יודע את התשובה, עדיף לו לנחש מאשר להשאיר ריק.
כך זה גם עובד במודלי השפה, הם “מתוגמלים” על ניחוש במקום על הודאה ב-“אני לא יודע”. למעשה, גם אם מאגר האימון היה מושלם, האלגוריתמים הסטטיסטיים שבהם משתמשים המודלים מחייבים שיעור מסוים של טעויות. לפי החישובים שלהם, עצם קיומם של “עובדות חד פעמיות” (כמו למשל ימי הולדת נדירים שהוזכרו רק פעם אחת בנתוני האימון), מבטיח מראש שיעור גבוה של הזיות סביב אותן עובדות.
אז למה הן לא נעלמות אחרי אימון נוסף?
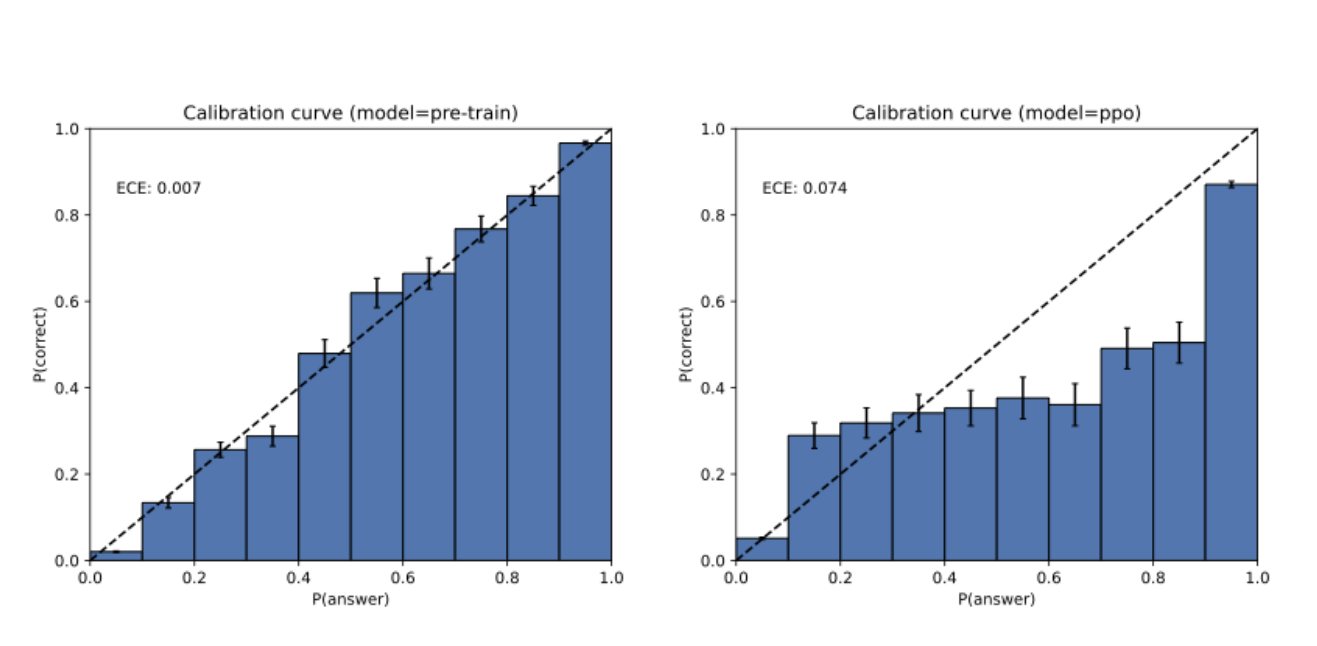
פשוט כי בשלב שלאחר האימון, המודלים מתוחזקים כך שיתנו תשובות יותר נעימות לשיחה ופחות שגויות. אבל כאן מתגלה פרדוקס: רוב מדדי הביצועים הקיימים בתחום מבוססים על ציונים בינאריים (נכון/לא נכון) שבהם אמירת “לא יודע” שווה לאפס.
המשמעות היא שמודל שמנחש תמיד יקבל ציון גבוה יותר ממודל זהיר שמעדיף להימנע מתשובה. כך נוצרה “מגפה של עידוד חוסר ודאות”, כפי שמגדירים החוקרים.
עמוד השדרה של החיפוש נשאר יציב
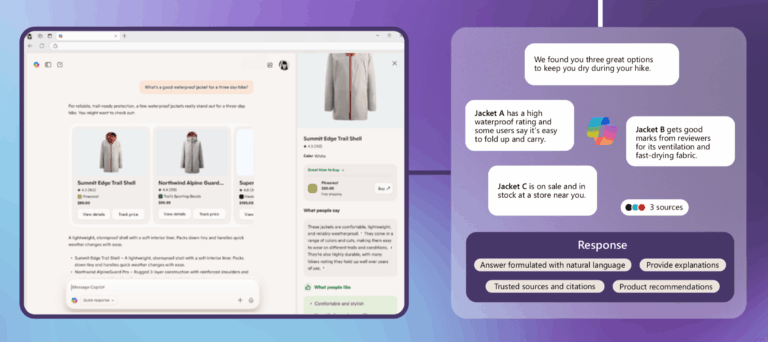
כפי שדן פטרוביץ’ מחברת Dejan מסביר במאמר שלו, מודלי שפה אינם מחליפים את מנועי החיפוש אלא מהווים שכבת הצגה (Presentation Layer). מנועי החיפוש עדיין עושים את “העבודה הכבדה”:
- זחילה (Crawl) של מיליארדי דפים.
- אינדוקס (Index) ליצירת מאגרי מידע יעילים.
- שליפה (Retrieve) של מסמכים רלוונטיים.
- דירוג (Rank) לפי סמכות והתנהגות משתמשים.
מודלי השפה לא מבצעים את עבודת החיפוש עצמה אלא את עבודת ההצגה: שכתוב שאילתות, סיכום מידע, הפקת תשובות מובנות והצגתם בצורה שיחתית. כלומר, הם שכבת הפרזנטציה של מנוע החיפוש, לא מנוע החיפוש עצמו.
עתיד החיפוש: היברידי
למרות הרעש סביב חיפוש AI, המחקר מזכיר שמודלי שפה לא מחליפים את מנועי החיפוש אלא מוסיפים שכבת הצגה מעליהם. שזו אגב בדיוק אותה המסקנה שעלתה במחקר האחרון של SEMrush שמצא כי שימוש ב-ChatGPT לא גרע מהחיפושים בגוגל אלא הרחיב אותם.
עבור אנשי SEO ו-GEO המשמעות היא כפולה: מצד אחד, אסור לוותר על התשתית הקלאסית (כיסוי תוכן, סמכות, עדכניות ואופטימיזציה), כי בלעדיה אי אפשר להופיע גם בשכבת התשובות של ה-LLMs. מצד שני, צריך להבין שהמודלים עצמם מועדים להזיות, ולכן ניהול נראות מותג בעידן החדש דורש חשיבה היברידית.
הפתרון נמצא בשילוב בין שני העולמות: לתת ל-LLMs חיבור לתוצאות חיפוש אמיתיות (RAG), לעבוד עם מאגרי ידע סגורים ומבוקרים כשצריך ולדרוש מהם גם לצטט מקורות. זה לא יגרום להזיות להיעלם לגמרי, כי כל עוד המודלים מתוגמלים על ניחוש מושכל ולא על זהירות תמיד יהיו פספוסים, אבל זה בהחלט מצמצם טעויות.
לסיכום, חיפוש לא הופך ל-AI בלבד ולא נשאר קלאסי בלבד, אלא שילוב של השניים. מנועי החיפוש ממשיכים להביא את העובדות, המודלים יודעים לארוז אותן יפה ולהציג בשפה טבעית, והמשימה של אנשי SEO/GEO היא לדאוג שהמותג שלהם יופיע בצורה אמינה ובולטת גם בזירת החיפוש החדשה.