בשנה האחרונה, כל מי שעוסק בשיווק דיגיטלי מרגיש את זה: החיפוש משתנה לנגד עיניו בקצב מהיר.
מודלי שפה גדולים (LLMs) כמו ChatGPT, Gemini ו-Perplexity כבר לא מציגים קישורים – הם נותנים תשובות סופיות במקום עמודי תוצאות. גוגל, בתגובה, משיקה את AI Overviews ואת AI Mode – גרסת העתיד של מנוע החיפוש שלה. ובעלי אתרים שואלים את עצמם: איך בכלל נוודא שאנחנו מופיעים שם?
זו שאלה שדיברתי עליה לעומק במדריך על GEO – אופטימיזציה למנועים גנרטיביים, אבל מאחורי כל זה מסתתרת שאלה עמוקה יותר:
איך בכלל המודלים האלה עובדים?
איך הם מחליטים אילו תשובות להציג? אילו פסקאות לצטט?
ואיך הם מבינים הקשר?
רוב האנשים אומרים לעצמם: “זה בינה מלאכותית, זה פשוט חכם יותר”.
אבל האמת היא שיש שם מנוע, מנגנון גאוני שפועל מאחורי הקלעים והוא נקרא Transformer.
פריצת הדרך הגיעה מגוגל, לא מ-OpenAI
לפני ש־OpenAI הפכה לשם שכולם מכירים, ואפילו לפני שמישהו ידע מה זה GPT הייתה גוגל.
בשנת 2017, צוות חוקרים מגוגל, חלקם מ-Google Brain וחלקם מ-Google Research, פרסם מאמר בשם “Attention Is All You Need”.
אם אתם עוסקים באופטימיזציה למנועים גנרטיביים (GEO) ועדיין לא קראתם אותו – זה הבסיס. חובה להכיר! אל תדאגו, המאמר הזה כאן יסביר לכם הכל בשפה פשוטה ולא מדעית
במבט ראשון זה נראה כמו עוד מאמר אקדמי, עמוס נוסחאות ומונחים. בפועל, זה היה רגע מכונן.
במקום להציע שיפור קטן למודלים קיימים, החוקרים הציעו לזרוק לפח (!) את כל המבנים המסורתיים של עיבוד שפה, כולל רשתות נוירונים חוזרות (RNNs) ו־LSTMs, ולהחליף אותם במודל חדש לגמרי, שנשען כמעט לחלוטין על דבר אחד: היכולת להתמקד (Attention).
אבל חשוב לדייק: השימוש ב-Attention לא היה חדש בפני עצמו. החידוש המהפכני היה שזה היה המודל הראשון שבנוי כולו אך ורק על מנגנוני Attention, בלי אף שכבת CNN או RNN (שעד אז נחשבו לאבני יסוד בעיבוד שפה).
זו הסיבה ששמו של המאמר הפך לסוג של הצהרה מהדהדת: Attention Is All You Need (“ואת כל השאר אפשר פשוט לשכוח”).
שנה לאחר מכן, גוגל שחררה בקוד פתוח את BERT, המודל הראשון שהביא את ארכיטקטורת ה-Transformer ליישום רחב בעולם האמיתי. משם, הפופולריות של הגישה החדשה המריאה, וה-Transformer הפך לארכיטקטורה המועדפת לכל משימת עיבוד שפה טבעית (NLP), בזכות היכולת שלו לפעול במקביל, להתאים לסקיילים עצומים, ולהבין הקשרים מורכבים.
אבל כאן מגיע הטוויסט.
למרות שגוגל היא זו שהביאה את הבשורה, הייתה זו דווקא OpenAI שזיהתה את הפוטנציאל השיווקי העצום, עטפה את זה היטב, והביאה לעולם את GPT – ראשי תיבות של Generative Pre-trained Transformer.
מודלים כמו ChatGPT, Claude, Gemini ועוד רבים מבוססים כולם על אותו עיקרון: ה-Transformer שהוצג לראשונה במאמר ההוא של חוקרי גוגל.
כך שלמרות שהציבור הרחב מקשר את מהפכת הבינה המלאכותית היוצרת ל־OpenAI, מי שבאמת הניח את היסודות היו המדענים של גוגל.
מה זה טרנספורמר ואיך הוא עובד?
העיקרון היה גאוני בפשטותו: במקום לעבד טקסט מילה אחר מילה כמו קורא סדרתי, טרנספורמר בוחן את כל המילים בו זמנית, ובודק עבור כל אחת מהן אילו מילים במשפט הכי רלוונטיות להבנת ההקשר שלה.
במקום לעבור שורה שורה, הוא מקבל את כל המשפט כמקשה אחת וחושב, לרוחב, על מי כדאי להסתכל, בכמה משקל, ובאיזו עוצמה.
התוצאה: מודל שהוא גם מהיר יותר, גם מדויק יותר, גם ניתן להקבלה (parallelization), ובעיקר סקיילבילי שמאפשר לאמן אותו על כמויות עצומות של טקסט בלי לאבד שליטה.
אבל מה שהופך את ה-Transformer למהפכה אמיתית זה לא רק מנגנון אחד, אלא המבנה השלם שלו.
המנוע בנוי משני חלקים מרכזיים:
- Encoder – החלק שאחראי להבין את הטקסט הקיים.
- Decoder – החלק שאחראי לייצר טקסט חדש, על בסיס מה שה-Encoder הבין.
למודל Transformer המקורי יש את שניהם.
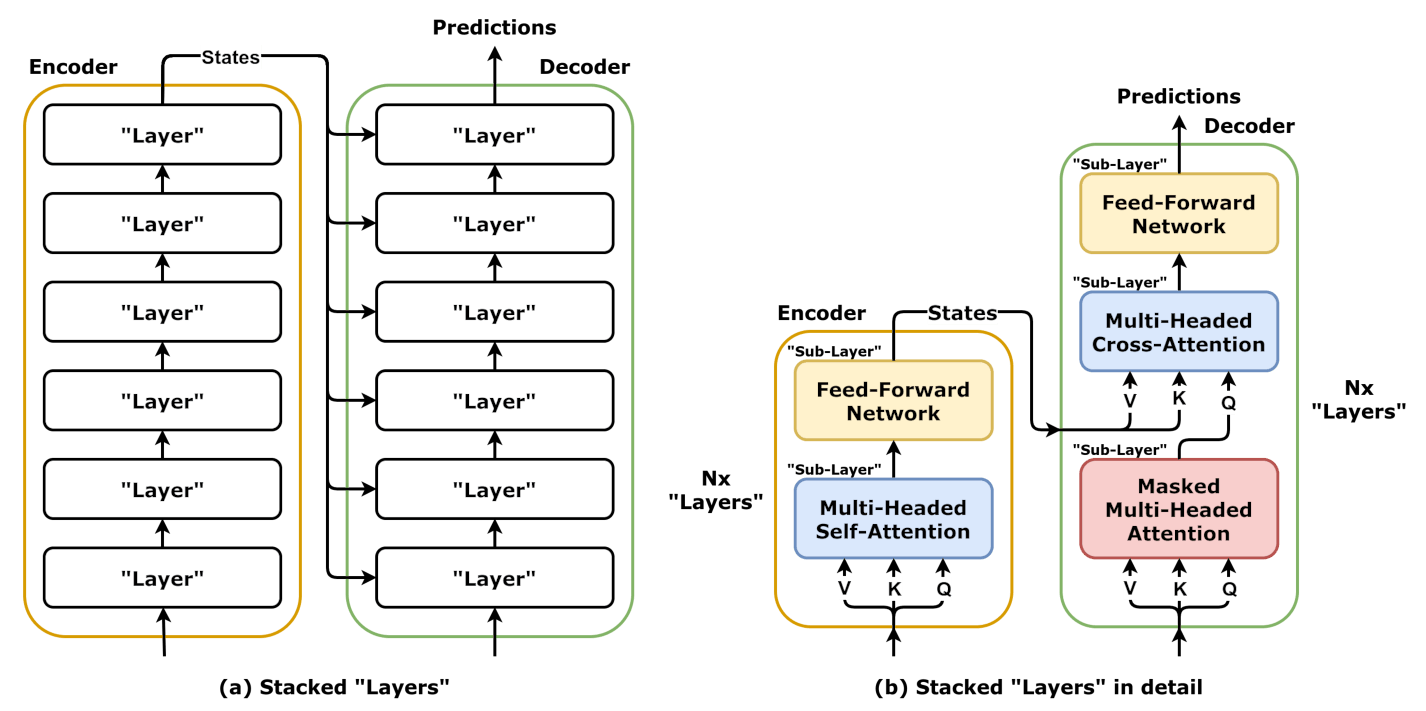
אבל חשוב לדעת, לא כל המודלים שאנחנו מכירים משתמשים בשניהם. לדוגמה, BERT משתמש רק ב-Encoder, ו-GPT משתמש רק ב-Decoder.
אז בואו נצלול קודם אל החלק הראשון ה-Encoder ונבין מהם המרכיבים שבונים אותו, ואיך הם יחד יוצרים הבנה עמוקה של שפה.
איך עובד ה-Encoder?
מרכיב 1: Self-Attention – כל מילה מתבוננת על שאר המשפט
כדי להבין איך זה עובד, נסתכל במשפט הבא:
“החתול רדף אחרי העכבר כי הוא היה רעב”
המילה “הוא” יכולה להתייחס לחתול או לעכבר, אז מה עושה הטרנספורמר?
- שלב 1: במקום לזכור איזו מילה הופיעה קודם, הוא שואל:
“מה הכי חשוב לדעת כדי להבין את ‘הוא’?”
“אולי כדאי להסתכל על המילה ‘חתול’? אולי ‘עכבר’? אולי ‘רעב’?” - שלב 2: הוא מחשב משקל לכל אחת מהמילים במשפט לפי מידת הרלוונטיות שלהן ל-“הוא”. כדי לאפשר את זה, כל מילה מומרת לשלושה רכיבים:
- Query (שאלה): מה אני מנסה להבין כרגע?
- Key (מפתח): מה יש לי להציע לאחרים?
- Value (ערך): מה המידע שאני יכולה לתרום אם בוחרים בי?
בדוגמה שלנו, המילה “הוא” יוצרת Query. היא שואלת בעצם: “מי כאן יכול לעזור לי להבין למה אני מתכוונת?” כל שאר המילים מציגות את ה-Key שלהן: “אני החתול”, “אני העכבר”, “אני רעב”.
- שלב 3: כעת המודל מחשב התאמה מתמטית בין השאלה (Query של “הוא”) לבין כל אחד מה-Keys. ככל שההתאמה גבוהה יותר, כך גדל המשקל שניתן ל-Value של אותה מילה, כלומר: לתוכן שהיא מביאה.
- שלב 4: בסוף התהליך, המודל משקלל את כל ה-Values, אבל לא שווה בשווה, אלא לפי אותם משקלי Attention. וכך, “הוא” מקבל ייצוג חדש – ייצוג שמבוסס על מה שהכי חשוב עבורו במשפט.
![]()
למה זה גאוני?
כי זו הפעם הראשונה שמודל שפה באמת מבין הקשר, לא כי הוא זוכר הכל, אלא כי הוא בוחן את כל האפשרויות בכל שלב מחדש.
ולא פחות חשוב, הכל מתבצע במקביל. כלומר אפשר לעבד משפטים, פסקאות וספרים שלמים תוך התייחסות עמוקה למשמעות, בלי סדר כרונולוגי מחייב.
מרכיב 2: Positional Encoding – לתת למודל תחושת זמן
עד עכשיו דיברנו על המודל כאילו הוא רואה את כל המילים יחד, וזה נכון אבל יש לזה גם חיסרון: איך הוא יודע באיזה סדר הופיעו המילים במשפט?
כשכל המילים נבחנות במקביל, עלולה ללכת לאיבוד התחושה ש-״החתול״ בא לפני ״רדף״, ושהמשמעות של המשפט תלויה בסדר הזה.
כדי לפתור את זה, מוסיפים לכל מילה קידוד מיקום, או באנגלית: Positional Encoding.
זה כמו להגיד למודל:
“רק שתדע, המילה ‘החתול’ הייתה ראשונה, ‘רדף’ שנייה, ‘העכבר’ שלישית, וכן הלאה”.
איך זה נראה בפועל?
לכל מילה מוסיפים מספרים קטנים שמייצגים את המיקום שלה, שילוב של מידע על המילה עצמה עם היכן היא במשפט.
המילים “הוא” ו”רעב” אולי קרובות אחת לשנייה, אבל בלי לדעת שהן מופיעות בסוף המשפט, קשה להבין שהן תוצאה של הרעב של החתול.
מרכיב 3: Feedforward – לתת עומק לכל מילה בנפרד
אחרי ש-“הוא” קיבל ייצוג חדש בעקבות ה-Self-Attention, הטרנספורמר לא עובר ישר הלאה, הוא רוצה לעבד את הייצוג הזה קצת יותר לעומק.
לכן, לכל מילה עוברת גם דרך רשת קטנה שנקראת Feedforward Neural Network, מין פילטר מתמטי אישי שמוסיף עוד עיבוד ומורכבות רק לאותה מילה.
אם Self-Attention אומר: “בוא נקשיב למה שקורה מסביב”.
אז Feedforward אומר: “עכשיו אני רוצה לעבד את מה שקיבלתי בעצמי, רגע לבד”.
בדוגמה שלנו:
לאחר ש-“הוא” קיבל משקלים מכל המילים במשפט, ה-Feedforward בודק האם יש תבניות פנימיות שיכולות לעזור לו להבין את עצמו טוב יותר. אולי משהו במבנה של “הוא + היה + רעב” שחוזר בטקסטים רבים ומצביע על מושא שמרגיש רעב, ולא מישהו אחר.
מרכיב 4: Layer Normalization ו-Residual Connections כדי לשמור על יציבות
העיבוד הזה חוזר על עצמו שוב ושוב, בכל פעם אנחנו מוסיפים שכבה נוספת של הבנה.
אבל כשעובדים עם כל כך הרבה שכבות, קל לאבד איזון. לפעמים מידע מתנפח או נעלם.
כדי למנוע את זה, בכל שלב מתווספים שני אלמנטים קריטיים:
- Residual Connection: שומר עותק מהמידע המקורי ומוסיף אותו חזרה, כמו להגיד “אל תשכח מאיפה באת”.
- Layer Normalization: מאזנת את הערכים כדי שלא יהיו קפיצות חזקות מדי במידע.
במילים אחרות – שומרים על “שפיות” בתוך כל שכבת הבנה.
מרכיב 5: שכבות על גבי שכבות, הבנה שמעמיקה בכל פעם
הקסם האמיתי של טרנספורמר קורה כשהבלוקים האלה נערמים זה על זה.
אחרי כל בלוק כזה (Self-Attention → Feedforward וכו’), המודל ממשיך לעבד את אותו משפט שוב, אבל עם הבנה עמוקה יותר.
במקום רק לשאול: “למי הוא מתייחס?”, בשכבות הגבוהות הוא כבר יכול להבין: “האם זה משפט על רעב? האם יש פה סיבה ותוצאה? האם יש פה רגשות?”.
אפשר לדמות את זה לשכבות עיבוד במוח:
- השכבה הראשונה מבינה מילים.
- השנייה מבינה משפטים.
- השלישית מבינה כוונה.
- הרביעית מבינה סאבטקסט.
וככה מתקבלות תשובות כמו אלו שאתה רואה ב-ChatGPT, שמצליחות לא רק להבין מילים, אלא גם משמעות, הקשר וכוונה.
לסיכום, הנה כל החלקים שמרכיבים את האנקודר בטרנספורמר ומה שכל אחד מהם עושה במסע להבנת משמעות:
| המרכיב | מה הוא עושה? | למה זה חשוב? |
|---|---|---|
| Self-Attention | כל מילה מחשבת את החשיבות של שאר המילים עבורה | מאפשר הבנת הקשר עמוק בין מילים בטקסט |
| Positional Encoding | מוסיף לכל מילה מידע על המיקום שלה במשפט | שומר על סדר המילים — קריטי להבנת משמעות |
| Feedforward Network | עיבוד נוסף של כל מילה בנפרד אחרי ה-Self-Attention | מוסיף מורכבות ועומק להבנה של כל מילה |
| Residual Connection | מוסיף חיבור בין ה״קלט המקורי״ לתוצאה החדשה | שומר מידע חשוב מהשלבים הקודמים ומונע איבוד הקשר |
| Layer Normalization | מאזנת את הערכים בתוך כל שכבה | שומרת על יציבות בחישוב ומונעת קפיצות חדות |
| שכבות מרובות (Stacked Layers) | חוזרים על אותם שלבים שוב ושוב עם אותן מילות הקלט | כל שכבה מוסיפה עומק — כמו מוח שחושב שוב ושוב עד שמבין טוב יותר |
איך עובד ה-Decoder?
אם תחשוב על זה, ה־Encoder רק מבין. הוא קורא, מנתח, שוקל משמעויות אבל הוא לא כותב שום דבר.
מי שאחראי לייצר את התשובה, מילה אחרי מילה, הוא דווקא החצי השני של הטרנספורמר: ה־Decoder.
נזכיר רגע את ההקשר: כל מודל כמו ChatGPT, Gemini או Claude מקבל שאלה מהמשתמש, מעבד אותה בעזרת Encoder, ואז בונה את התשובה דרך Decoder, כמו סופר דינמי שמחבר מילה אחר מילה.
אז איך זה עובד?
גם בדקודר יש Self-Attention, אבל שונה
בדומה לאנקודר, גם כאן כל מילה מתבוננת על אחרות כדי להבין את ההקשר, אבל יש פה מגבלה קריטית: ה-Decoder לא יכול “להציץ קדימה” ולראות את המילים שעדיין לא נוצרו. הוא רואה רק את מה שכבר נכתב.
לכן הוא משתמש במה שנקרא Masked Self-Attention – מנגנון שמונע ממנו לשקול מילים עתידיות כשהוא כותב את המילה הנוכחית.
ואז מגיע Cross-Attention, לחבר את ההבנה לשאלה
עד עכשיו הדקודר הסתכל רק על עצמו. אבל רגע, איך הוא יידע מה המשתמש שאל בכלל?
פה נכנס מנגנון שנקרא Cross-Attention: כל מילה שהדקודר מנסה לכתוב, יכולה “להציץ” פנימה לתוך מה שהאנקודר הבין, ולשאול: “מה מתוך השאלה רלוונטי כדי לנסח את התשובה שלי?”.
זה כמו שיש לו שני מקורות מידע: מה כבר נכתב עד עכשיו בתשובה ומה היה חשוב בשאלה המקורית, והוא שוקל את שניהם בכל מילה חדשה שהוא יוצר.
אחר כך Feedforward ו-Normalization
כמו באנקדור, גם פה ממשיכים עם אותו מבנה:
- רשת Feedforward שנותנת עומק
- Normalization ששומר על יציבות
- וחיבור Residual שמונע איבוד מידע
וככה נולדת תשובה – כל פעם נוצרת מילה אחת חדשה, ואז היא מצטרפת לרשימת המילים הקיימות, וככה הדקודר ממשיך לייצר את התשובה מילה אחר מילה, עד שהוא מגיע לסיום.
לסיכום, אלו המרכיבים של הדקודר:
| מרכיב | מה הוא עושה? | למה זה חשוב? |
| Masked Self-Attention | כל מילה מתחשבת רק במה שנכתב לפניה, ולא במה שיבוא אחריה | שומר על הסדר ההגיוני של יצירת הטקסט — מילה אחר מילה |
| Cross-Attention | כל מילה מתבוננת על הפלט של האנקודר כדי להבין מה נשאל | מאפשר ליצור תשובה שמבוססת על השאלה או ההקלט |
| Positional Encoding | מוסיף מידע על המיקום של כל מילה בתשובה | משמר את סדר המילים — קריטי להבנת התחביר |
| Feedforward Network | עיבוד אישי נוסף לכל מילה | מעמיק את היכולת להבין ולדייק את המשמעות |
| Residual Connection | שומר חלק מהמידע המקורי ומוסיף אותו חזרה לפלט | מונע איבוד מידע חיוני במהלך השכבות |
| Layer Normalization | מאזן את ערכי המידע בתוך השכבה | שומר על יציבות ומונע חריגות בקלטים או פלטים |
| שכבות מרובות (Stacked Layers) | חוזרים שוב ושוב על כל התהליך | מאפשר הבנה עמוקה, הדרגתית ומורכבת יותר של התשובה |
איך מתקבלות ההחלטות במודל?
בואו נבין רגע את הדיקודר פרקטית.
כשמודל כמו ChatGPT או Gemini מנסה לבנות תשובה, הוא לא באמת “יודע” מה נכון או שגוי. מה שהוא כן יודע זה לחשב הסתברות.
בכל שלב של יצירת תשובה, המודל שואל את עצמו:
“בהתחשב במה שכבר כתבתי, ומה שהבנתי מהשאלה, מה המילה שהכי סבירה לבוא עכשיו?”
כדי לקבל את ההחלטות האלה, הוא נשען על שלושה עקרונות הסתברותיים מרכזיים:
- חיזוי לפי הסתברות (Next Token Probability): המודל בוחר בכל שלב את המילה שההסתברות שלה הכי גבוהה להופיע בשלב הזה.
- למידה מהקשרים חוזרים (Statistical Co-occurrence): אם שתי מילים (או רעיונות) מופיעות הרבה יחד, המודל לומד לקשר ביניהן.
- נוכחות סמנטית עקבית (Semantic Proximity): אם מילה מסוימת מופיעה שוב ושוב ליד רעיונות דומים, המודל יזהה אותה כמתאימה להשלמה במצבים דומים.
דוגמה 1: תשובה כללית (ללא מותג)
נניח שהמשתמש שאל:
“מה אוכלים חתולים?”
והמטרה של הדקודר היא לבנות את התשובה:
“חתולים ניזונים בעיקר מבשר”
איך נראה התהליך?
- שלב 1: אין עדיין מילים. המודל מתחיל מהטוקן <start> ומנבא את המילה הראשונה.
→ שוקל את ההבנה של השאלה (מה אוכלים חתולים) ובוחר: “חתולים” - שלב 2: יש מילה אחת – “חתולים”. עכשיו המודל מנבא את המילה הבאה:
→ מבוסס על ההקשר שחתולים הם נושא, סביר להוסיף פועל: “ניזונים” - שלב 3: עם “חתולים ניזונים” הוא צריך להוסיף תיאור:
→ משלים: “בעיקר” - שלב 4: עם “חתולים ניזונים בעיקר”, מה הכי סביר לבוא עכשיו בהקשר של מזון?
→ מנבא: “מבשר”
חשוב לדעת: גם כאן שלושת העקרונות ההסתברותיים פועלים. רק שבמקום לבחור שם מותג, המודל בוחר את הרצף שהכי הגיוני להופיע לפי מיליוני טקסטים בהם למד.
דוגמה 2: תשובה שכוללת מותג
עכשיו נניח שהמשתמש שאל:
“מה המלון הכי טוב למשפחה עם ילדים ביוון?”
והמודל מחזיר:
“Ikos Olivia נחשב לאחד המלונות המובילים למשפחות עם ילדים ביוון”
איך זה קורה?
- פענוח השאלה: ה־Encoder מייצג את השאלה בצורה מופשטת: נושא (מלון), אוכלוסייה (משפחה עם ילדים), מיקום (יוון).
- חיפוש התאמה: ב־Decoder המודל שואל “מה המילה שהכי סביר שתתחיל את התשובה?”
→ לפי סטטיסטיקות, ההסתברות הגבוהה ביותר היא ששם של מלון יופיע כאן. - ולמה דווקא Ikos Olivia? כאן נכנסים שלושת העקרונות:
- Next Token Probability: זו המילה שהכי הגיוני לבוא אחרי השאלה הזו.
- Statistical Co-occurrence: במיליוני מסמכים, היא מופיעה יחד עם “משפחה”, “ילדים”, “יוון”.
- Semantic Proximity: יש לה הקשר סמנטי ברור עם ביטויים כמו “חוף ידידותי”, “מומלץ למשפחות”, “ריזורט יוקרתי”.
- המשך המשפט: אחרי שהוזכר Ikos Olivia, שאר המשפט נבנה לפי אותו עיקרון – המילה הבאה שהכי מתאימה להשלמה.
לסיכום: איך הבנה עמוקה של ה־Transformer עוזרת ל-GEO?
אחרי שהבנו איך ה־Transformer באמת עובד, אפשר סוף סוף לחבר את זה לעולם האמיתי שלנו כאנשי שיווק.
וזה החיבור החשוב: המודל לא בוחר את התשובה מתוך מאגר, לא סורק את האינטרנט בזמן אמת, ולא עובד עם רשימה של אופציות.
הוא פשוט חוזה את המילה הכי סבירה לבוא עכשיו, בהתבסס על מה שלמד ממיליארדי פסקאות.
וזה בדיוק המקום שבו אנשי GEO (אופטימיזציה למנועים גנרטיביים) יכולים להשפיע על התשובות עצמן.
שני עקרונות שהכי קל לנו לעבוד איתם כמו שראינו בחלק הקודם:
- Statistical Co-occurrence: אם נגרום לכך שהמותג שלנו יופיע שוב ושוב בהקשרים מסוימים, כמו “המלון הכי טוב למשפחות”, “יוון עם ילדים”, “מומלץ לחופשה משפחתית” וכו’, המודל ילמד לקשר בין השאלות האלו לבין השם שלנו.
- Semantic Proximity: אם נדאג לפזר מסביב למותג שלנו ביטויים עשירים, עקביים ורלוונטיים לתחום שלנו, כמו “ריזורט יוקרתי”, “ידידותי לילדים”, “גישה לחוף”, אנחנו נגרום למותג להרגיש כחלק טבעי מהתשובה.
זה לא על “לקבל קרדיט”. זה על להיות הבחירה הסבירה ביותר.
ככה אנחנו לא רק מופיעים בשיחה, אנחנו נבחרים כאילו זה ברור מאליו.
עוד טיפים איך ליישם את זה בפועל במדריך המקיף על אופטימיזציה למנועים גנרטיביים – GEO.