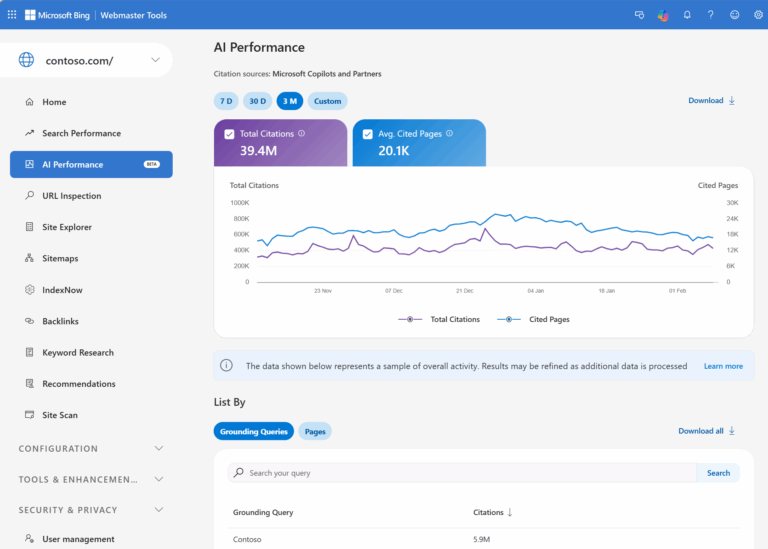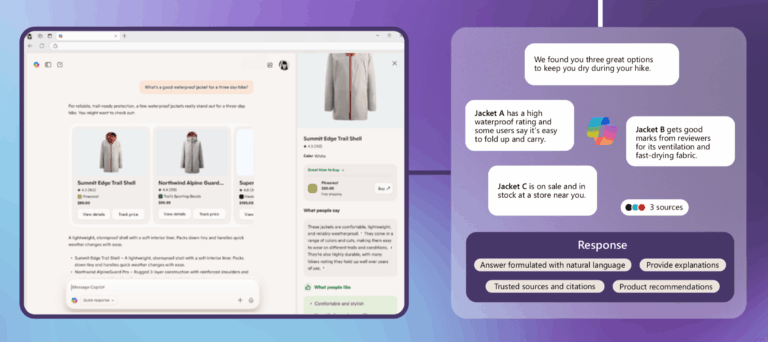
בשבוע שעבר Cloudflare הודיעה שהיא מתחילה לבחון מודל “Pay Per Crawl” למודלי AI, מהלך שמסמן עידן חדש שבו תוכן נחשב למשאב יקר שצריך לשלם עליו. לאט לאט מתחדדת ההבנה שלא רק חשוב היכן כותבים, אלא איך נתפסים בעיני המודל. הקריטריונים להשתלבות בתשובות משתנים, והם נשענים יותר על סמנטיקה, קוהרנטיות וייצוג עומק נושאי, הרבה מעבר ל-SEO המסורתי. השינוי הזה הוא חלק ממעבר עמוק ומהותי שמתרחש בתעשיית החיפוש, מעבר ממילות מפתח למשמעות (Semantic Search).
בעבר, SEO היה משחק של התאמות מדויקות: אם המשתמש כתב “ביטוח רכב זול”, זה בדיוק מה שנכתב מבחינת מנוע החיפוש. כיום, עם ההתקדמות ב-NLP ובמודלי שפה גדולים (LLMs), מנועים מנסים להבין מה המשתמש באמת רוצה, גם אם הוא לא ניסח זאת במדויק (Intent).
התוצאה היא שמנועים לא מחפשים התאמה מילולית, אלא סמנטית. אם כתבת על “פוליסת נהג חדש משתלמת” והמשתמש מחפש “ביטוח ראשון לצעירים”, אתה כמותג ביטוח עשוי להופיע, רק אם הווקטורים שלך קרובים מספיק.
איך המנוע הגנרטיבי באמת בוחר אותך?
כדי להבין איך להיכנס לתוך תשובה של מנוע גנרטיבי כמו ChatGPT, Gemini, Perplexity וכו’, צריך לחשוב כמו המודל עצמו.
מאחורי הקלעים פועלים כמה מנגנונים מרכזיים: ייצוג וקטורי (Vector Embedding), פיצול שאילתות (Query Fan-Out), ומודל הפקה מסוג RAG. כולם מבוססים על עקרונות של ארכיטקטורת ה-Transformer, אותה טכנולוגיה שעומדת בבסיס המהפכה של מודלי השפה הגדולים. המנגנונים האלו עובדים יחד כדי לנתח את כוונת המשתמש, לשאול שאלות פנימיות, לשלוף מידע סמנטי מדויק ולבנות ממנו תשובה.
ייצוג וקטורי (Vector Embeddings)
מאחורי הקלעים, כל טקסט באתר מתורגם לייצוג מספרי שנקרא וקטור. כלומר הפיכת טקסט למיקום במרחב רב ממדי, כך שניתן לחשב קרבה סמנטית בין פסקאות, משפטים או מונחים.
למשל, אם כתבת מאמר על “השוואת מחירי ביטוח לרכב חשמלי”, והמשתמש מחפש “איזה ביטוח הכי מתאים לטסלה?”, המודל לא מחפש התאמה מילולית, אלא קרבה וקטורית. אם הפסקה שלך קרובה לווקטור של השאלה, היא תישלף.
כל פסקה באתר שלך היא נקודה במרחב המשמעות. ככל שהיא סמנטית יותר, חדה יותר ונכתבת בשפה טבעית, כך הווקטור שלה מדויק יותר, והסיכוי שתיבחר עולה.
פיצול שאילתות (Query Fan-Out)
לפני מספר חודשים גוגל השיקו את AI Mode ותיארו את המונח Query Fan-Out באופן הבא:
“AI Mode uses our query fan-out technique, breaking down your question into subtopics and issuing a multitude of queries simultaneously on your behalf. This enables Search to dive deeper into the web than a traditional search on Google, helping you discover even more of what the web has to offer and find incredible, hyper-relevant content that matches your question.”
מודלים גנרטיביים לא עונים על שאלה כמו שהיא, אלא מפרקים אותה למספר תתי שאלות והתהליך הזה נקרא Query Fan-Out.
למשל, אם מישהו שואל “מה היתרונות והחסרונות של מכונית חשמלית?”, המודל יפרק את השאלה לתתי שאלות לפי סיווגים כמו עלויות, טעינה, ביצועים וכו’.
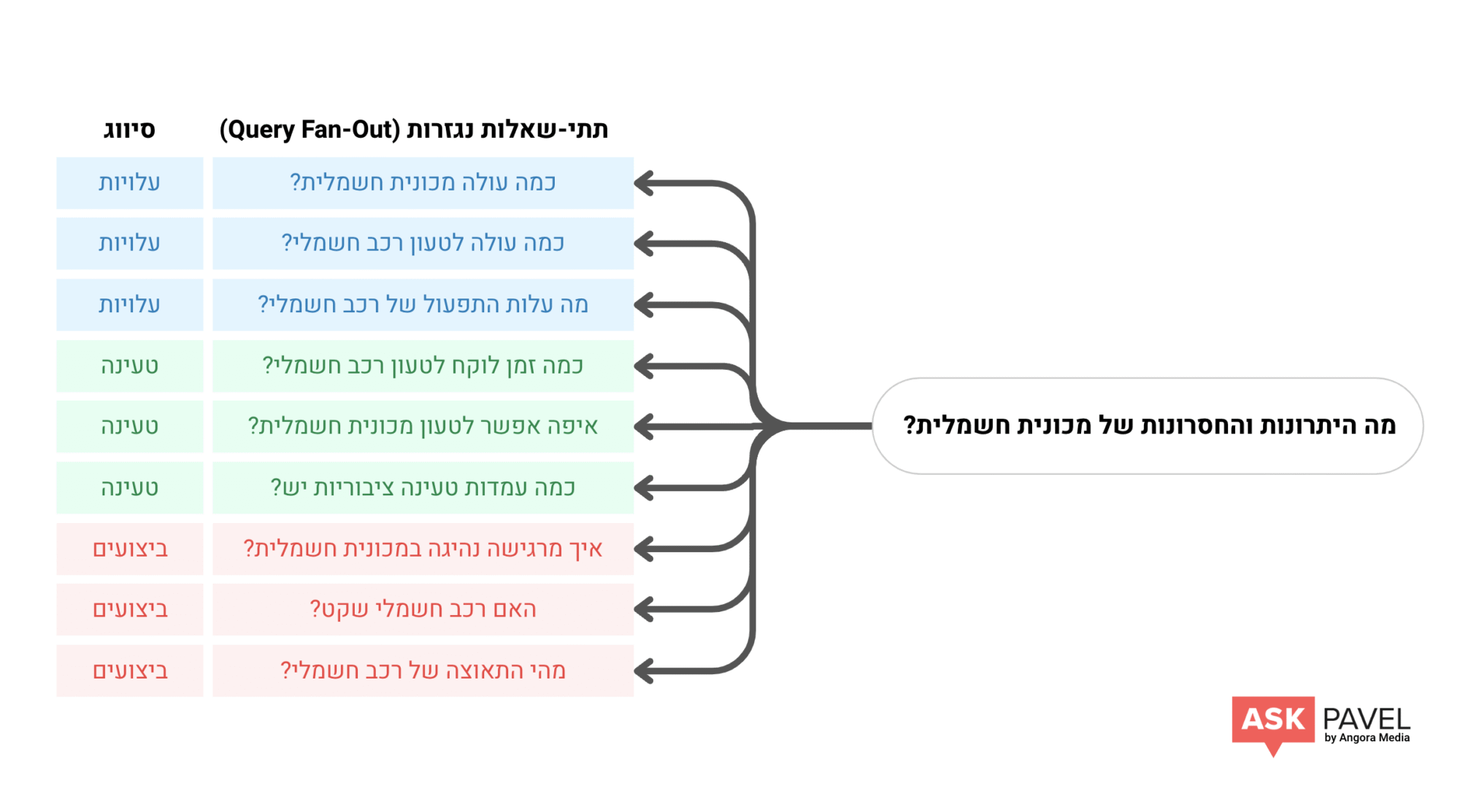
אם יש לך עמוד (או כמה עמודים) שעונה על ההיבטים האלו באופן ברור, עקבי וסמנטי תוכל להופיע בתשובה, גם אם לא שלטת בביטוי הראשי. נוכחות בתתי שאלות היא המפתח לחדירה אל תוך גוף התשובה.
הפקה מבוססת שליפה (Retrieval-Augmented Generation – RAG)
השלב שבו הפסקאות שלך באמת נכנסות למשחק מתרחש בטכנולוגיה שנקראת “יצירה מבוססת אחזור” (או RAG – ראשי תיבות של Retrieval-Augmented Generation). זהו מודל שבו המערכת קודם כל שולפת מסמכים רלוונטיים, ואז מייצרת תשובה על בסיסם.
שלב ה-“Retrieval” מבוסס על קרבה וקטורית בין השאלה או תת-השאלה, לבין הפסקאות באינטרנט או במאגר הנתונים של המערכת. אם הפסקה שלך לא מספיק דומה במשמעות, היא פשוט לא תישלף. גם אם היא מצוינת מבחינת SEO ונכתבה על ידי מומחה בתחום.
יותר מזה, ככל שהאתר שלך עקבי סמנטית (כל הפסקאות שייכות לאותו קלסטר רעיוני), כך גובר הסיכוי שהמערכת תשלוף ממנו תשובות כל פעם מחדש.
אחידות וקטורית = סמכות נושאית (Topical Authority)
המשמעות של כל זה היא שסמכות נושאית כבר לא נמדדת רק לפי כמות העמודים או מילות המפתח אלא לפי עד כמה התכנים שלך מדברים שפה רעיונית עקבית.
אם אתה כותב על ביטוח, אבל חצי מהתכנים מתמקדים בהשוואות, רבע בשיווק אגרסיבי ועוד רבע בחוות דעת, המודל רואה אותך כלא עקבי. אבל אם יש לך עשרות עמודים שמתמקדים בזוויות שונות של אותה שאלה מרכזית – אתה הופך לסמכות (ולא בגלל הכמות אלא בגלל האחידות הווקטורית).
מבחינת המודל אתה “נשמע כמו מישהו שמבין” ולכן יש סיכוי גבוה שתיבחר בתשובות.
אז איך יוצרים אחידות כזו בפועל?
הבנת החשיבות של אחידות סמנטית זה שלב ראשון, אבל השלב הקריטי הוא יישום בפועל. הנה ארבע פעולות מרכזיות שכל בעל אתר, כותב תוכן או מקדם GEO צריך לבצע כדי להבטיח שהתוכן שלו מדבר “בקול אחד” בעיני מנועי ה-AI.
1. ניתוח embedding של האתר: תראה איך המודל רואה אותך
השלב הראשון הוא לבחון את התוכן שלך מנקודת המבט של המודל.
באמצעות כלים כמו Vector embeddings של OpenAI או Vertex AI (ה-API של Gemini), או כלי קוד פתוח חינמיים כמו word2vec או GloVe, ניתן להפוך כל פסקה באתר שלך לווקטור – ייצוג מתמטי של המשמעות הסמנטית שלה.
לאחר מכן, אפשר להשתמש בכלי ויזואליזציה כמו TensorFlow Embedding Projector (כלי חינמי של גוגל) כדי למפות את הפסקאות על גבי גרף דו־ממדי.
סרטון הדרכה קצר שמסביר איך להשתמש במערכת:
החסרון ב-TensorFlow הוא שזה דורש ווקטורים בפורמט מסוים (TSV), לחלופין אפשר להשתמש בכלים אחרים כמו Nomic Atlas או InfraNodus שהם כמובן לא חינמיים ויש להם עקומת למידה מסוימת.
אז אם אחרי הבדיקה אתה רואה קלאסטרים ברורים וצפופים זה סימן טוב: התוכן שלך אחיד ורלוונטי נושאית. אם רואים פיזור רחב ועננים מנותקים, זו נורת אזהרה: התוכן שלך מתפזר רעיונית ועלול להיתפס כלא סמכותי או לא ממוקד בעיני המודל.
הבדיקה הזו הופכת ליסוד של כל אסטרטגיית GEO מודרנית.
2. בניית קלסטרים סמנטיים ברורים: סדר פנימי = סמכות חיצונית
מנועים גנרטיביים לא אוהבים עמודים כלליים מדי. הם מחפשים עומק ממוקד סביב תתי-נושאים ברורים. לכן חשוב לבנות את האתר סביב קבוצות תוכן (content clusters) שמתמקדות כל אחת בזווית ייחודית של התחום המרכזי.
לדוגמה, באתר שעוסק בביטוח במקום עמוד אחד על “ביטוח רכב”, נרצה ליצור עמודים על:
- ביטוח לרכב חשמלי
- ביטוח לנהגים צעירים
- ביטוח מקיף לעסקים קטנים
- וכו’…
כל אחד מהעמודים הללו יתרום לקלסטר הסמנטי הכללי שלך, ויחזק את המרכז הווקטורי של האתר. התוצאה: המודל יזהה אותך כמי שיש לו עומק, ארגון וראייה כוללת בתחום. זו כמובן גם המלצה שרלוונטית לעולמות ה-SEO, מפרקים את המונח הגנרי לביטויי זנב ארוך וסביב כל אחד מהם מייצרים עמוד שנותן למשתמש מענה מקיף על אותו נושא.
3. אופטימיזציה לקישורים פנימיים לפי קרבה רעיונית
במנועי החיפוש הקלאסיים, קישורים פנימיים עוזרים לגוגל לזחול באתר, להבין מבנה, להעביר סמכות ולהחליט אילו עמודים חשובים.
אבל במנועים גנרטיביים, המודל לא “מטייל” באתר כמו זחלן אלא נחשף רק לעמודים שמועברים אליו מפורשות בשלב האחזור (Retrieval), שהוא השלב הראשון של מנגנון RAG עליו דיברנו מקודם.
במנגנון הזה, כשהמשתמש שואל שאלה, המערכת לא תמיד מסתמכת רק על מה שהמודל “זוכר” מהאימון (training), אלא מפעילה חיפוש בזמן אמת לרוב דרך מנוע חיפוש חיצוני. רק העמודים שהמערכת מחזירה כ”מותאמים ביותר לשאלה” מועברים הלאה לשלב הבא, שבו המודל קורא אותם ומסכם או מחבר תשובה.
אם העמוד שלך לא נשלף בשלב האחזור, מבחינת המודל הוא לא קיים. גם אם הוא כתוב מעולה, SEO/GEO Friendly, הוא פשוט מחוץ לפריים של התשובה.
לכן, הקישורים הפנימיים לא משמשים כאן לזחילה או אינדוקס כמו במקרה של הזחלן של גוגל, אלא בעיקר לצורך:
- חיזוק ההקשר הסמנטי של העמוד בעיני המודל
- רמיזה על עומק ועקביות
- הכנסת תוכן נוסף לתוך התשובה, אם הוא חלק מהטקסט הנשלף
דוגמה: אם יש לך עמוד על “ביטוח לסטודנטים” שבתוכו מופיע קישור עם טקסט עוגן כמו “השוואה בין פוליסות גילאי 18-25 מכלל החברות” והקישור הזה מוביל לעמוד שממש מרחיב על הנושא, אז גם אם המודל לא ייכנס לקישור, עצם האזכור המפורש של ההקשר תורם להבנה שהאתר שלך מקיף וקוהרנטי סביב נושא מסוים.
ניתן להשתמש בכלים של חיפוש וקטורי (כמו Weaviate, Pinecone או FAISS בקוד פתוח) כדי למצוא עמודים באתר שלך שקרובים סמנטית זה לזה. ככה זה עובד בשלבים:
- חתוך את כל התוכן באתר לפסקאות.
- הפוך כל פסקה ל־Embedding Vector.
- הרץ חיפוש וקטורי: אילו פסקאות הכי דומות זו לזו.
- חבר ביניהן בעזרת קישורים פנימיים רק אם יש קשר רעיוני ברור.
כך תיצור קלסטרים פנימיים חזקים, שגם אם לא יסרקו במלואם, עדיין משדרים למודל תמונה של אתר ממוקד ועקבי.
4. שימוש עקבי בטרמינולוגיה
בעבר הנטייה הייתה לפזר מילים נרדפות ולהשתמש במונחים שונים שמתארים את אותו הדבר כדי לכסות כמה שיותר שאילתות חיפוש. אולם, בעידן מודלי ה-AI והחיפוש הסמנטי של גוגל, התמונה השתנתה. מודלים מתוחכמים מבינים קונספטים ורעיונות ולא רק התאמות מילוליות ולכן אחד הגורמים שמחזקים משמעותית את הקוהרנטיות הסמנטית של התוכן הוא שימוש עקבי ודיוק בטרמינולוגיה.
פיזור שפה על ידי שימוש במונחים רבים ושונים לתיאור אותו רעיון כמו “פוליסה”, “כיסוי” ו”הגנה ביטוחית”, עלול דווקא לגרום למודל לראות בך מקור פחות ממוקד. הוא עלול לבלבל את הווקטור הסמנטי של המושג ובעצם להחליש את ה”אות” המגיע מהתוכן שלך לגבי אותו רעיון ליבה.
כדי למנוע זאת ולחזק את האחידות הסמנטית מומלץ:
- להגדיר מראש רשימת מונחים מרכזיים (Core Terms) עבור נושאי הליבה שלך.
- להשתמש בהם בעקביות בכל עמודי האשכול הרלוונטיים.
- להימנע מניסוחים שיווקיים משתנים רק לצורך גיוון (גיוון לשוני יתר עלול דווקא לפגוע בבהירות הסמנטית).
מודלי ה-AI של היום מעריכים עקביות ודיוק מושגי שחוזר על עצמו באופן טבעי. גישה זו לא רק מסייעת ל-AI להבין את התוכן שלך לעומק ולשלוף אותו ביעילות, אלא היא גם תואמת באופן מלא את עקרונות ה-SEO המודרני. היא בונה סמכות נושאית, משפרת את הרלוונטיות של התוכן שלך בעיני גוגל, ובכך תורמת לדירוגים טובים יותר גם בתוצאות החיפוש המסורתיות וגם בחשיפה בתשובות AI.
סיכום: לא רק התוכן חשוב אלא המבנה הסמנטי שלו
כשהמודלים הגנרטיביים מחליטים את מי לכלול בתשובה, הם שואלים את עצמם “למי יש גוף ידע ברור, עקבי, ואמין בנושא הזה?”.
אתרים שמתפזרים רעיונית נראים להם כמו רעש. אתרים ששומרים על עקביות סמנטית בין פסקאות, בין עמודים, ובין נושאים נתפסים כעוגן של הבנה.
ובמבט קדימה, המגמה רק תתחדד: מנועי חיפוש צפויים להכניס התאמה אישית למרחב הווקטורי, כך שתכנים יישלפו לא רק לפי השאלה אלא גם לפי מי ששואל אותה. סטודנט עשוי לראות ניסוח קליל ופרקטי, בעוד מנהל בכיר יקבל גרסה מקצועית וממוקדת יותר.
במציאות הזו, היכולת לבנות קלסטרים קוהרנטיים לפי נושא, לשמור על שפה אחידה, ולהציע עומק ממוקד תהיה רק השלב הראשון. השלב הבא הוא להוסיף שכבת ניסוח מותאמת לקהלים שונים, כך שכל תוכן לא רק ידבר על הנושא הנכון אלא גם ידבר בצורה הנכונה לקורא הנכון.